We studied the ability of deep neural networks (DNNs) to restore missing audio content based on its context. We focused on gaps in the range of tens of milliseconds, a condition which has not received much attention yet. The proposed DNN structure was trained on audio signals containing music and musical instruments, separately, with 64-ms long gaps. The input to the DNN was the context, i.e., the signal surrounding the gap, transformed into time-frequency (TF) coefficients. Two networks were analyzed, a DNN with complex-valued TF coefficient output and another one producing magnitude TF coefficient output, both based on the same network architecture. We found significant differences in the inpainting results between the two DNNs. In particular, we discuss the observation that the complex-valued DNN fails to produce reliable results outside the low frequency range. We demonstrated a generally good usability of the proposed DNN structure for generating complex audio signals like music.
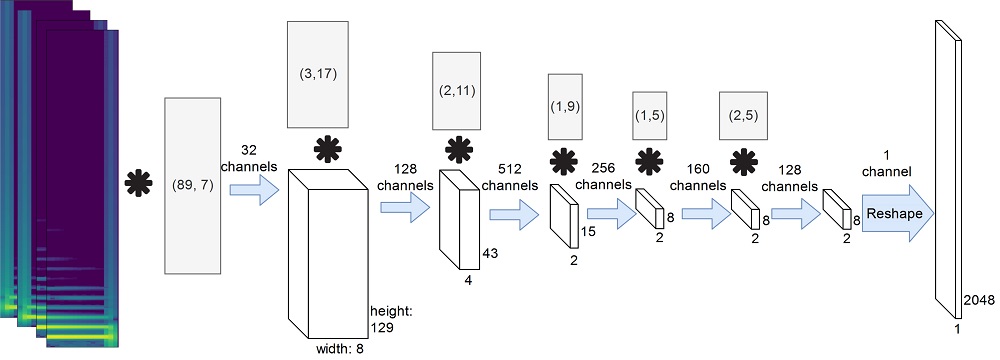
Encoder architecture:
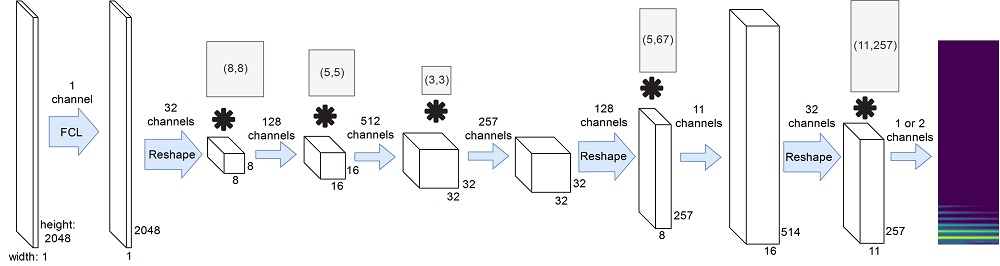
Decoder architecture:
Now we introduce sound examples generated with the network. They are divided into three classes according to our perception of them. These are: good, noisy and faded. The faded class presents samples where we hear as if the algorithm did a fade-in and fade-out on the gap.
Good examples
On this example, we find a string signal with a few harmonics. Both networks achieve reconstructions which are difficult to detect.
Left: Ground truth
Center: Magnitude (28.7 dB SNRms)
Right: Complex (20.9 dB SNRms)
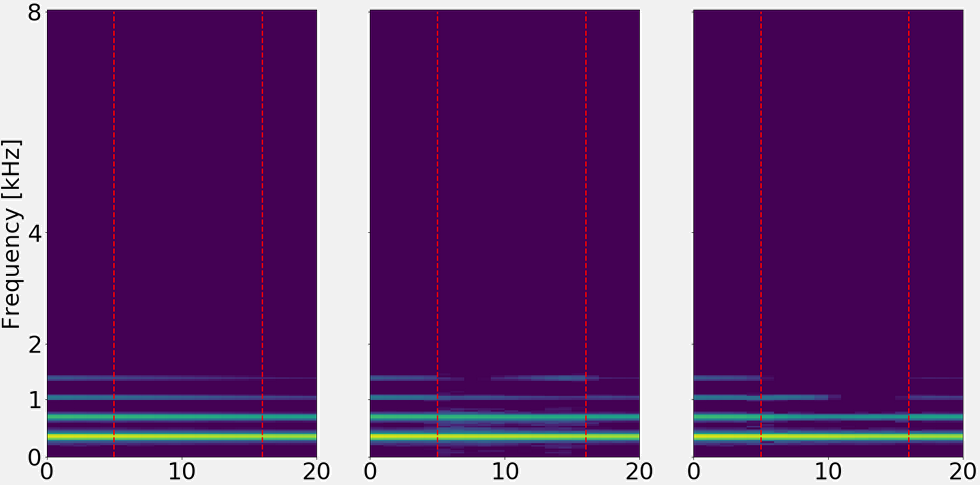
This example features a synthesized string signal, with several harmonics and a constant vibrato. Both networks achieve reconstructions that are difficult to detect.
Left: Ground truth
Center: Magnitude (29.2 dB SNRms)
Right: Complex (27.3 dB SNRms)
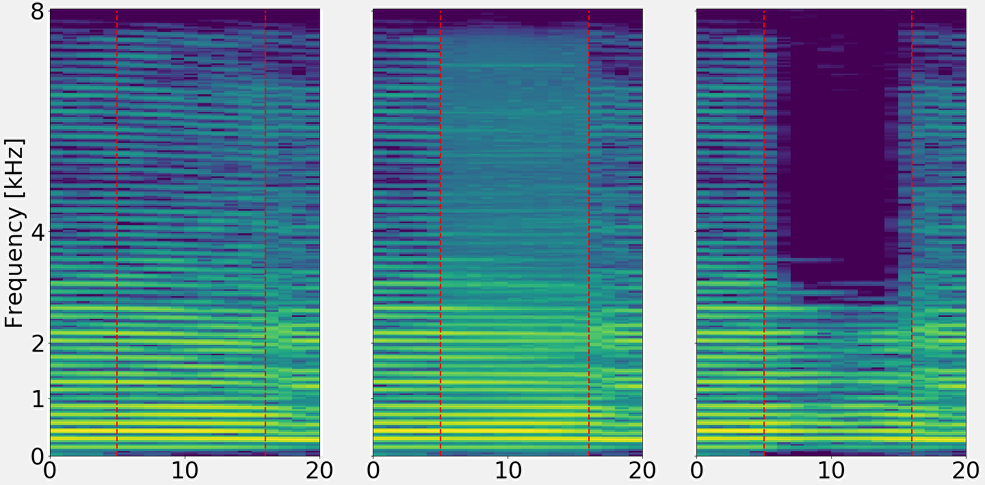
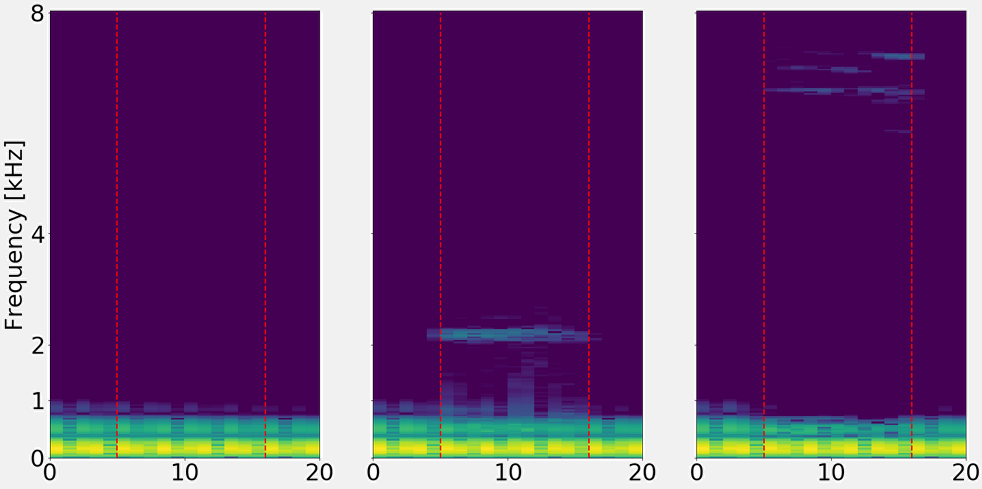
On this example, we find a trumpet signal with a lot of information on high frequencies. Neither of the networks achieve very high SNRms values, nevertheless, it is quite hard to hear any artifacts.
Left: Ground truth
Center: Magnitude (11.4 dB SNRms)
Right: Complex (4.1 dB SNRms)
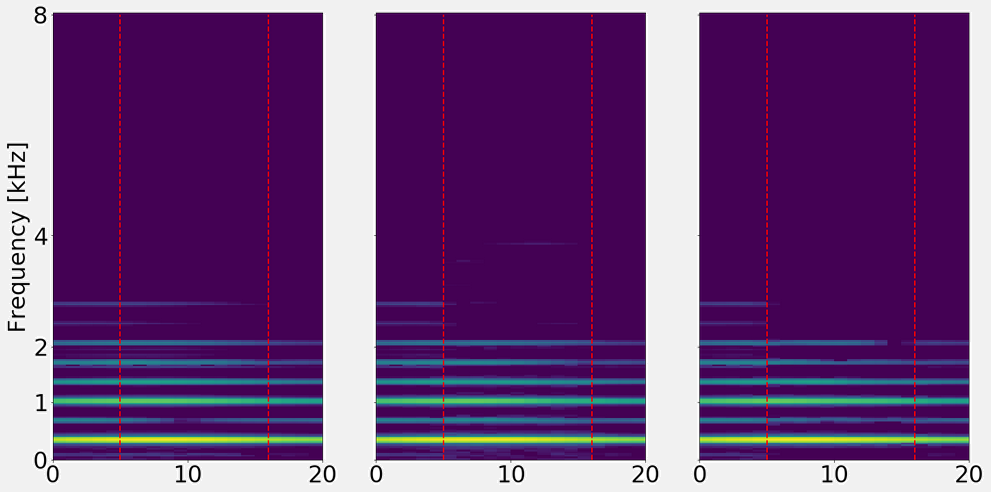
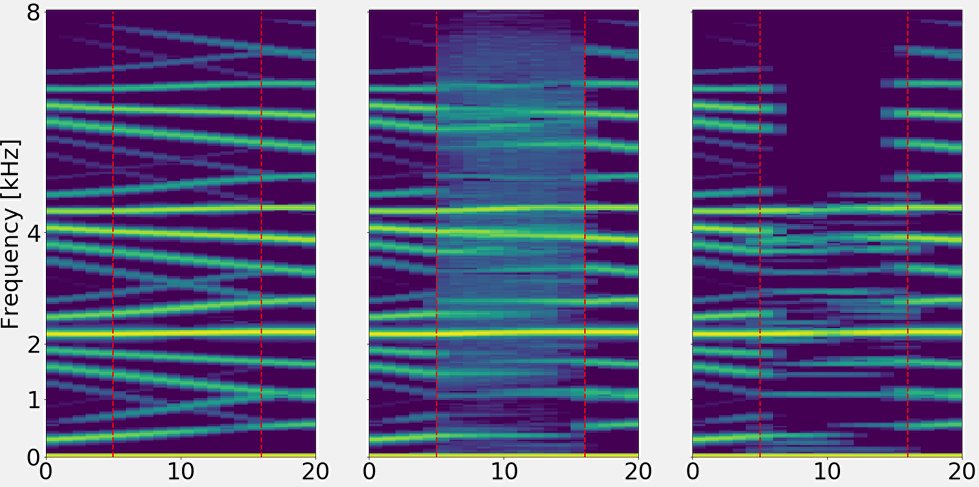
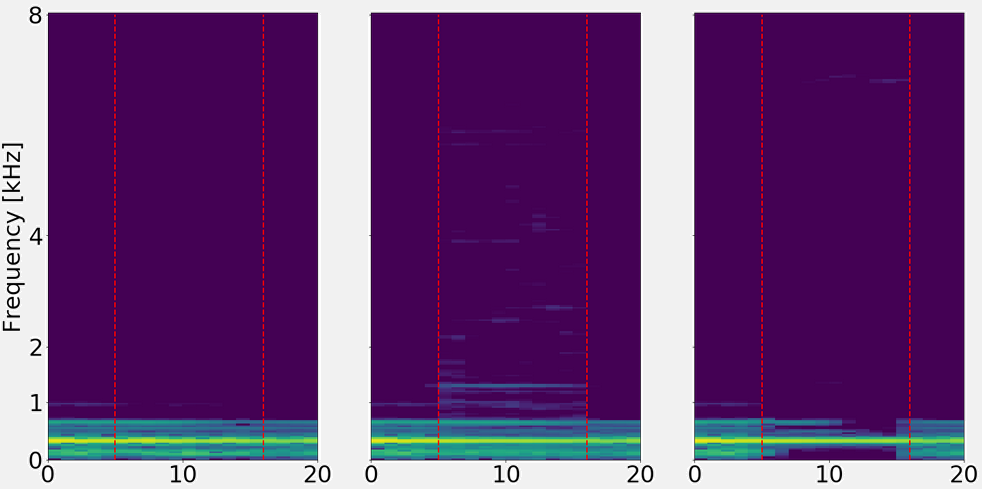
On this example, we find a synthetic signal with a lot of modulations. Both networks represent this modulations in some way.
For the magnitude network, even on very high frequencies the modulations are still inpainted.
For the complex network, above 5Khz there is little information.
Left: Ground truth
Center: Magnitude (7.8 dB SNRms)
Right: Complex (5.1 dB SNRms)
Faded examples
On this example, we find a pulsated string signal. Both networks achieve very high SNRms values, but they both present a faded artifact.
This is quite easy to hear for the complex network and it is not as present for the magnitude network.
Left: Ground truth
Center: Magnitude (35.2 dB SNRms)
Right: Complex (29.6 dB SNRms)
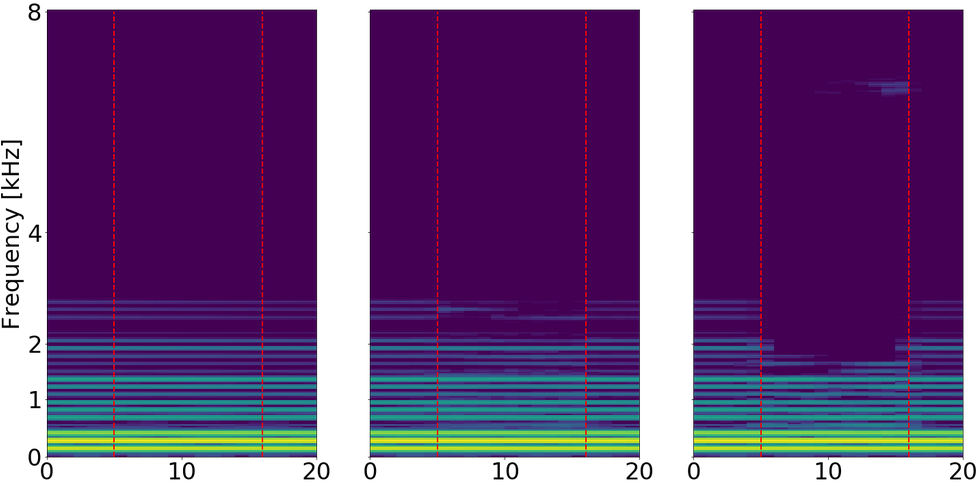
On this example, we find a string signal. Again we find a faded artifact that is clearer on the complex network than the magnitude network.
In this case, the SNRms are quite low.
Left: Ground truth
Center: Magnitude (8.7 dB SNRms)
Right: Complex (2.9 dB SNRms)
Noisy examples
Here we find a very low frequency synthesized signal. A clear noise burst can be heard on the gap.
Left: Ground truth
Center: Magnitude (13.7 dB SNRms)
Right: Complex (10.3 dB SNRms)
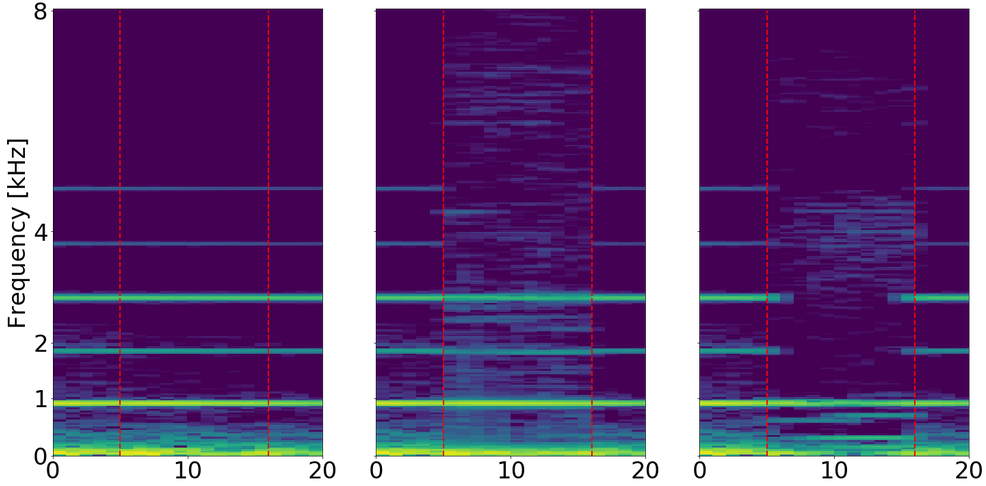
Here we find a low frequency signal. Interestingly, the magnitude network produced a harmonic that is not present on the original signal, and which can be clearly heard.
The complex network's reconstruction also has a noisy characteristic, but it is not as obvious.